
Data Labeling.
DSGVO konform.
Deutsch.
Annotation und Data Labeling als Full Service für Unternehmen
WARUM WIR
Wir verstehen Sie.
Lassen Sie jetzt Ihre deutschen Dokumente annotieren und labeln.
DSGVO
konform labeln
Deutschsprachige
Labeler
Von KI Experten
für KI Entwickler
DATA LABELING IM FULL SERVICE
WIR KÜMMERN UNS UM ALLES.
Vom Start bis zum Launch — alles inklusive.
Entlasten Sie mit unserem Full Data Labeling Service Ihre KI-Entwicklung.
1
Onboarding
Willkommen. Ihr persönlicher Projektmanager erstellt mit Ihnen eine Roadmap inklusive Prozessablaufplan, Projektdefinition, Labeling und Launch.
2
Datenübermittlung
Für Ihren Datenupload erhalten Sie einen abgesicherten Zugang zu unserer Private Cloud. Diese wird in einem Rechenzentrum bei Frankfurt gehostet.
3
Annotation/Labeln
Wir arbeiten nach den Vorgaben Ihrer Labeling Dokumentation und erstellen einen festen Zertifizierungsplan für Ihr Projekt.
4
Produktion
Unser deutsches Labeling-Team wird 100% auf Ihr Projekt eingebunden. Durch einen festen Projektmanager überwachen wir Ihre KPI‘s und Ziele im Labeling Prozess.
5
Revision
Wir verbessern stetig unsere Prozesse und passen unser Labeling Ihren Wünschen an.
6
Launch
Übergabe aller gelabelter Daten. Ihre KI-Entwickler können jetzt loslegen.
UNSERE PREISE
Einfache Berechnung.
Transparente Kosten.
Nutzen Sie unseren individuell zugeschnittenen Data Labeling Service
zur Dokumenten-Analyse für Texterkennung und Labeling von Bild- und Videodaten.
Standard
FULL DATA LABELING SERVICE-
Texterfassung
-
min. 500 Seiten
-
bis zu 10 Keyfields
Individuelle Lösung
NACH VORGABE-
Text-, Bild- oder Videolabeling
-
Ab 1.000 Seiten
-
Individuelle Keyfield-Anzahl
ÜBER MICHAEL BAUNER CONSULTING SERVICES
KI-ENTWICKLUNG
MUSS SMARTER WERDEN.
Seit 2005 nehmen wir IT-Infrastrukturen für Unternehmen in Betrieb. Seit 2020 stellen wir unseren Kunden individuelle KI-Lösungen zur Verfügung. So ermöglichen wir Unternehmen schon heute, das volle Potenzial von Künstlicher Intelligenz auszuschöpfen.
FAQ
Was bedeutet Data Labeling?
Das sogenannte „Data Labeling“ ist ein wichtiger Teil der Datenvorbereitung für Machine Learning. Dabei geht es um die Kennzeichnung von Daten aus Text, Audio, Bild und Video sowie dem Hinzufügen von weiteren Informationen und Metadaten.
Insbesondere beim Supervised Learning werden sowohl Eingabe- als auch Ausgabedaten für die Klassifizierung beschriftet. Sie dienen als Lerngrundlage für zukünftige Optimierungen von Machine Learning Modellen.
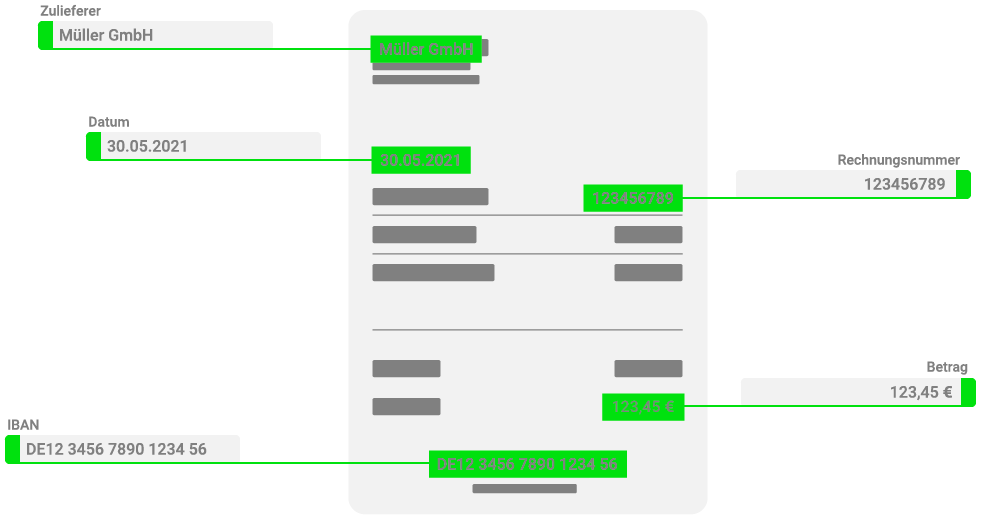
Was sind Labels beim Machine Learning?
Für das maschinelle Lernen werden Informationen aus Rohdaten (Dokumente wie: Bilder, Textdateien, Videos usw.) identifiziert, klassifiziert und gelabelt. Sogenannte „Labels“, wie z.B Datum, Rechnungsbetrag, Absender, etc…. werden als Informationen (Tags) den Rohdaten/Dokumenten hinzugefügt. Machine Learning Modelle können diese gelabelten Daten dann als Lerngrundlage nutzen.
Was sind gelabelte Daten?
Gelabelte Daten sind markierte/gekennzeichnete Formate, die mit einem oder mehreren Labels (Tags) versehen wurden. Ein Datalabel kann beispielsweise angeben, ob ein Foto eine Ente oder ein Huhn zeigt oder ob ein Punkt in einer Röntgenaufnahme ein Tumor ist.
Die Beschaffung von gelabelten Daten ist wesentlich teurer, als die Beschaffung von ungelabelten Rohdaten.
Wie labelt man Daten?
In der Regel manuell. Sogenannte Data-Labeler sind Personen, die beispielsweise alle Bilder in einem Datensatz kennzeichnen. Zum Beispiel, ob die Frage: „Enthält das Foto ein Pferd?“ zutrifft.
Wie bereitet man Daten für Machine Learning vor?
Bei der sogenannten „Datalabeling“ werden Rohdaten (Dokumente) so gekennzeichnet, dass Datenwissenschaftler und Analysten sie als Lerngrundlage für Algorithmen des Machine Learning nutzen können.
Die Modelle für maschinelles Lernen stützen sich dabei auf vier Hauptdatentypen. Dazu gehören numerische Daten, kategorische Daten, Zeitreihendaten und Textdaten.
Wie viele Textdaten benötigt man für eine Klassifizierung?
Für die Klassifizierung mit Deep Learning gilt als Faustregel: 1.000 Bilder/Dokumente pro Klasse, wobei diese Zahl deutlich sinken kann, wenn man vortrainierte Modelle verwendet.
Selber Labeln vs. Full Label Service
Das Labeln von Daten ist zeit- und ressourcenaufwendig. Bei einem externen Full Label Service verrichtet geschultes Fachpersonal den Schritt des Data Labeling.
In dieser Zeit können interne Ressourcen effizienter eingesetzt werden, was in der Regel kostengünstiger und zeitsparender ist.
Labeln vs. Annotieren
Labeln und Annotieren sind von der gleichen Herkunft. Annotieren beschreibt den Vorgang beim labeln, praktisch wie gelabelt wird. Also welches Ziel wird beim labeln verfolgt, was soll aus den vorliegenden Daten gemacht werden.
Beim Labeln werden die bestehenden Daten bei dem bereits das Ziel definiert wurde (annotiert) durch Label angereichert damit eine Künstliche Intelligenz daraus Muster erkennen kann und fortlaufend daraus lernen kann.